 The Society of Robotics and Automation is a society for VJTI students. As the name suggests, we deal with Robotics, Machine Vision and Automation
The Society of Robotics and Automation is a society for VJTI students. As the name suggests, we deal with Robotics, Machine Vision and Automation
The Magic of Neural Networks- How Machines Learn and Make Decisions
Mentees :
———————————-
Introduction
We usually take normal day-to-day activities like walking, running, eating, etc. for granted, but this is all a result of the mind-blowing learning process adapted by our brain and the nervous system. It is literally amazing how a mesh of neurons come together to enable us to perform each of our daily activities as well as empower our creative, logical, and analytical thinking. How would it be if we could implement similar actions in machines? Surely, it would accelerate the progress of humanity. This is what we aim to understand and implement in this unique project.
What are Neural Networks?
The process of creating Artificial Intelligence starts from its basic unit - ‘Neuron,’ which does all the computations and produces the final result. Artificial Intelligence is enacted by means of Neural Networks. It consists of one neuron for each input feature forming the input layer, several more layers of neurons for the ‘thinking’ part, and finally, a set of output neurons, which basically tell the probability of the input being one from the set of given categories. Using this intelligent classification, neural networks can be used in several areas, like, for instance, predicting the next action of a self-driving car based on its visual input.
How Do Neurons Work?
A neuron does two types of computations: first, calculating a linear function using the inputs from the previous layer, and second, applying a non-linear function to it, which prevents the neural network from just computing only a linear function of the input. This non-linearity is provided by means of activation functions, which include sigmoid, tanh, ReLU, Leaky ReLU, softmax, etc. However, the learning occurs by changing the weights and biases, which are used in the linear part of the computation of the neuron, and tuning them to their optimum values; this is done in each step of training the model on various examples.
The Learning Process
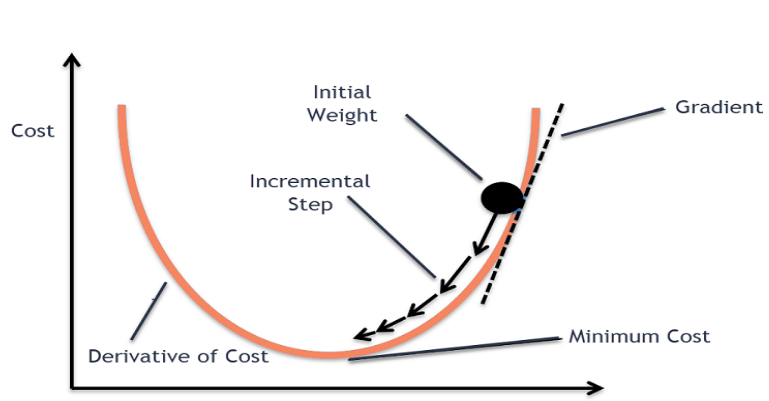
Depending on the final output produced by the model, its ‘loss,’ i.e., how close or away the prediction is from its actual value, for each training example, is calculated. Averaging the losses, we get the ‘cost’ function. Our aim is to minimize the cost function; hence, we use the process of gradient descent to tune weights and biases such that the cost function becomes minimum. This is the essence behind the learning process of artificial intelligence.
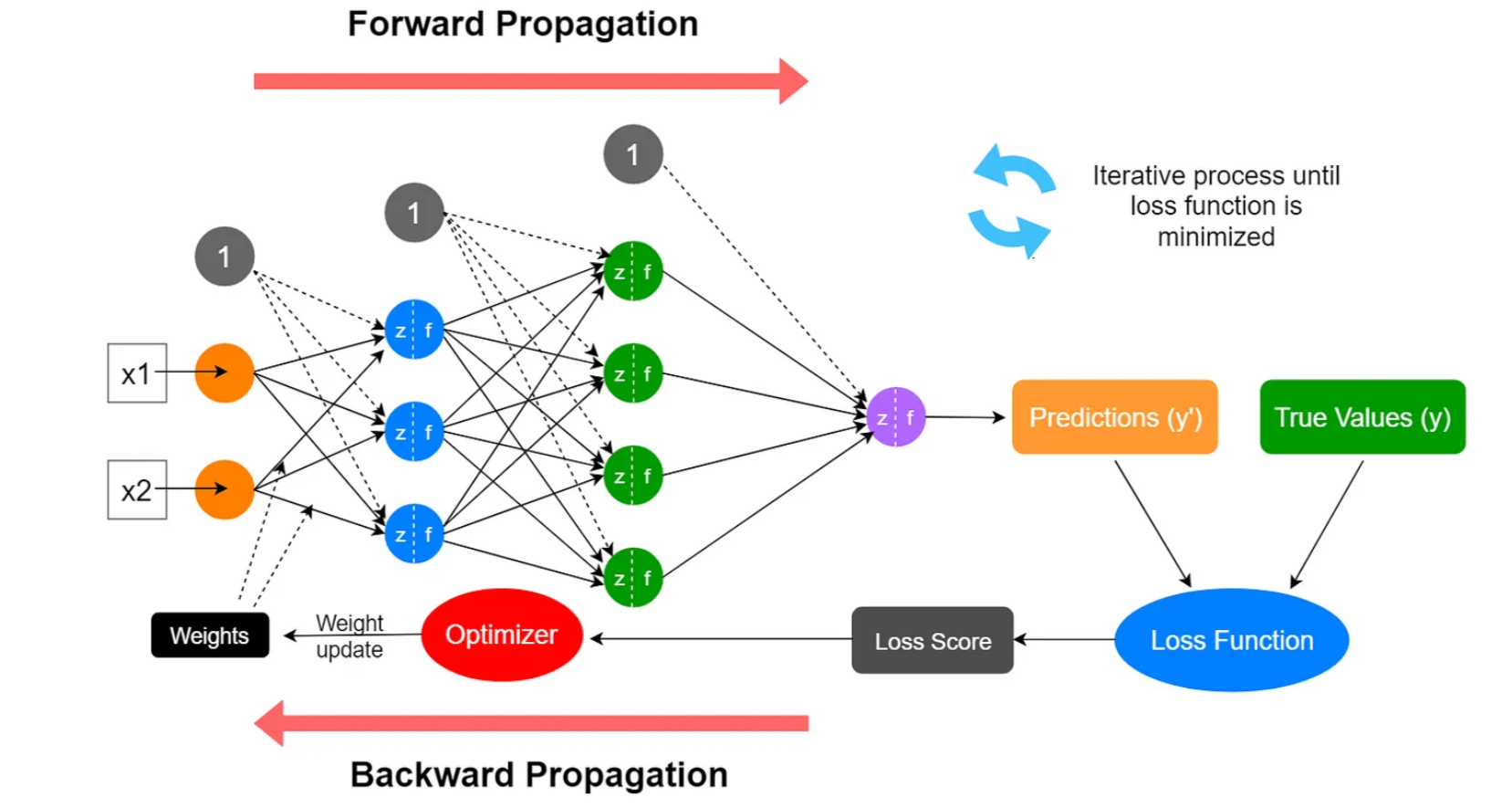
Hyperparameters
Hence, weights and biases are the parameters of this model. There exist certain other parameters on which the tuning of these parameters depends. Such parameters are termed ‘Hyperparameters.’ Some of the hyperparameters include the learning rate, momentum, number of hidden layers, number of middle units (neurons) in various layers, etc. Tuning the hyperparameters optimizes the neural network.
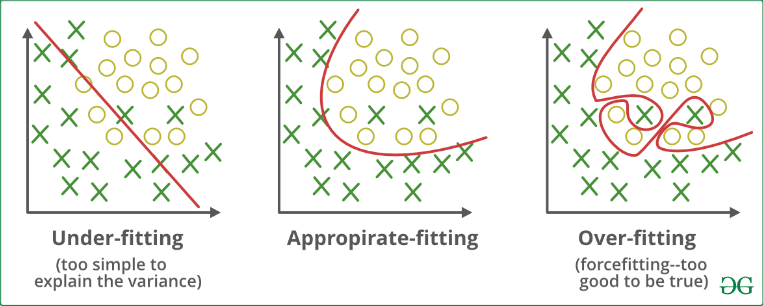
Bias and Variance
When the neural network performs poorly on the training set, it inevitably performs poorly on the development set. Such inaccuracy indicates high bias. When the neural network overtrains on the training set, it becomes less generalized and hence performs relatively poorly on the development set. This is a case of high variance. It is optimum to have low bias and low variance.
Conclusion
Neural networks are a powerful technology that has revolutionized the field of artificial intelligence. By understanding how they learn and make decisions, we can unlock their full potential and create innovative solutions to complex problems. As we continue to advance in this field, we can expect to see even more impressive applications of neural networks in the future.
Progress Until Now
Learned about Git and GitHub: Familiarized with version control and collaborative coding. Studied Linear Algebra and Deep Learning: Watched 3Blue1Brown’s series (YouTube) and took notes.
Completed Course 1: Neural Networks and Deep Learning in the Deep Learning Specialization (Coursera).
Gained foundational knowledge in deep learning.
Topics covered :
1) Neural Networks, Forward and Backward Propagation, Activation Functions, Gradient Descent, and Model Evaluation.
2) Worked on creating Neural Networks from scratch using NumPy and Pandas libraries. 3) Implemented and trained models from scratch using only NumPy.
Datasets:
MNIST dataset (digits 0-9) Masked gestures dataset (classifying from 11 types of Hand Gestures)
Completed Course 2: Improving Deep Neural Networks: Hyperparameter Tuning, Regularization, and Optimization.
Advanced understanding of deep learning techniques and applications.
Topics covered:
1) Hyperparameter Tuning, Bias and Variance, Regularization (Dropout, L2), Normalization, Exponentially weighted averages, Optimization Algorithms (Adam, RMSprop, Mini-Batch Gradient Descent, Stochastic Gradient Descent, Gradient Descent using Momentum), and some basics of TensorFlow.
Upcoming :
Our next step involves implementing a Vision Transformer from scratch. The Vision Transformer (ViT) is an advanced model that applies the transformer architecture, originally designed for natural language processing, to vision tasks. This model has demonstrated exceptional performance on image classification benchmarks and has the potential to revolutionize computer vision.
In this project, we will further:
1) Implement the Vision Transformer model from scratch using Python and PyTorch.
2) Train the model on image datasets and evaluate its performance.
3) Extend the model to generate descriptive captions for provided images.
– Github Repository for the project
Stay tuned for more updates as we delve into the fascinating world of Vision Transformers!